


The road leading to LLM Security Alignment

Development Trends of LLM (Large Language Model)
The dual paths of generalization and specialization are developing in parallel
General large models are capable of handling diverse tasks with large parameters, strong generalization, and multi task learning ability, and meanwhile having the ability to understand and generate across modalities. Specialized industry models are developed in specific fields to play an indispensable role.
Specialized industry models delve into finance, government affairs, and healthcare by optimizing and refining specific industries to meet their special needs, not only can the parameter scale be reduced, but also to streamline, have lower cost advantages, and be able to deeply integrate the internal of enterprises or institutions
Specialized large models can deeply integrate internal data of enterprises or institutions, providing highly accurate services for actual business scenarios. With the deep application and promotion of large models in vertical industries, their enormous potential value will be more widely recognized and reflected.
The complementary development of cloud-edge-end models
The cloud side LLM, with its powerful computing power and massive data, provides various abilities such as language understanding and knowledge Q&A, serving both individual and enterprise users. The end side LLM, due to its relatively low cost, strong portability, and high data security, is widely used in terminals such as mobile phones and PCs, focusing on the personal market and providing exclusive services, demonstrating broad market prospects. The "cloud-edge-end" hybrid computing architecture optimizes computing power allocation to achieve large-scale model training on the cloud side, real-time data processing on the edge side, and efficient and secure inference on the end side. It not only alleviates the pressure on cloud servers, but also meets users' needs for low latency, high bandwidth, lightweight, and privacy. This distributed computing approach provides new possibilities for large-scale model applications, indicating the future development direction of AI technology.
Open source of large models has become a new trend
In recent years, many enterprises and research institutes have opened sourced their developed large models, which not only promotes the vitality of the industry, but also brings significant convenience and efficiency improvement to small developers.
By calling open source LLM, small developers can significantly improve programming efficiency, accelerate the landing of AI applications, and eliminate complex training and adjustment steps, while improving coding, error correction efficiency, and code quality.
Agile governance has become a new governance pattern
In the practice of global model governance, agile governance, as an emerging and comprehensive governance model, is receiving widespread attention. This model is characterized by flexibility, fluidity, agility, and adaptability, which can quickly respond to changes in the environment and advocate for the joint participation of multiple stakeholders.
At the same time, a global pattern of multi-party collaborative governance of artificial intelligence has been formed, in which international organizations and national governments play a key role, jointly promoting the healthy development of artificial intelligence through building collaborative governance mechanisms, adjusting regulatory organizational structures, and improving governance tools.
When implementing governance strategies, flexible ethical norms and hard laws and regulations should be combined to construct a sound governance mechanism, effectively regulating the risks of large-scale models and promoting a balance between innovation and safety.
The ubiquitous artificial intelligence and AGI are coming
Artificial Intelligence from the perspective of End Users and Application Scenarios
In the future, ubiquitous artificial intelligence agents will be able to freely combine and match signal forms such as text, audio, video, and images, and interact with the external world for input and output, just like humans. This combination of media forms brings unparalleled convenience, but also introduces new security risk attack surfaces.
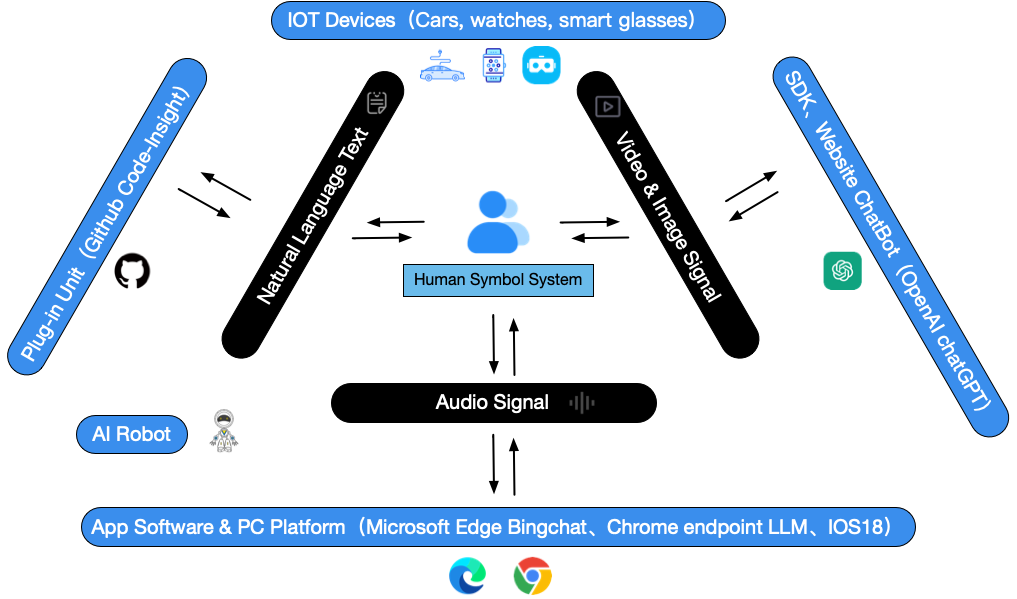
Artificial Intelligence from the perspective of GenAI capability providers
Regardless of the medium or carrier of operation, the input signal will ultimately be summarized in GenAI LLM. In theory, the security risks of GenAI LLM are the most complex, mainly reflected in the following aspects:
Cloud computing platform
computer room security
physical equipment security
operating system security
network security
..
AI infra
basic network security
data security
permission control
model security
office network anti intrusion
..
General LLM
content security
data leakage
hijacking attack
..
Industry domain LLM
industry compliance
content security
copyright issues
privacy data leakage
customized business risk control
..
GenAI Application
compliance supervision
business compliance
prompt hijacking
customer data leakage
content security
deep content fake
Challenges faced by ubiquitous artificial intelligence and AGI
The risks mainly come from several aspects:
Challenges of controllability and interpretability
LLM is essentially a probabilistic model, which has many problems such as unreliable generated content and uncontrollable capabilities.
LLM may generate false or meaningless information while following grammar rules. In addition, the greater challenge lies in the significant challenges of probabilistic fusion and secure alignment between different media signals, as well as the demand for secure adversarial corpora.
The impact on social ethics and morality
At the individual level, the challenges of LLM involve multiple important dimensions such as information acquisition, personal dignity, and emotional ethics.
One is that the application of large models has exacerbated the "information cocoon" effect. The large model, through its unique information presentation mechanism, makes individual information acquisition more passive and cognitive limited. At the same time, biases and discrimination in the training data of large models also affect the fairness of their generated results, which has a negative impact on fairness and justice.
The second is that the abuse of LLM technology will threaten human dignity. Criminals use large models to generate false content, engage in online bullying, insults, and rumors, causing mental and financial losses to victims. In addition, individuals' excessive dependence on large models also hinders their personal development, which may lead to a decline in learning ability and cognitive level, posing a threat to the potential for social development.
Thirdly, emotional computing technology brings ethical risks and disrupts interpersonal relationships. This new type of application simulates characters and sets their emotions or psychological states, which may have profound impacts on personal behavior, social relationships, and ethical and moral fields. It may lead to improper guidance of personal emotions, behaviors, and values, challenging the ethical and moral system of human society.
The challenge of user privacy and trade secret leakage
At the enterprise level, large models face multiple risk challenges such as user privacy and trade secret leaks, copyright infringement, and data security.
One is the increased risk of leakage of user privacy and trade secrets. Due to excessive user authorization, unauthorized use of information, and hacker attacks, the application of LLM has led to an increased risk of user privacy and trade secret leakage. User agreements often grant companies excessive personal information usage rights, which increases the risk of privacy breaches. Meanwhile, trade secrets may also be leaked due to employee violations or hacker attacks.
The second is the risk of copyright infringement caused by massive amounts of text and image data. Without a standardized licensing mechanism, large models may infringe upon multiple rights of the original work during content generation. If the generated content is highly similar to the original work, it may also constitute "substantial similarity" infringement.
The third issue is that traditional data collection methods pose data security risks. If user data is transmitted to a remote server for processing, there is a risk of data leakage.
The challenge of complex data flow pipelines
LLM is widely present in various stages of software workflows and technology stacks.
After pre-processing, analysis, API interface calls, GenAI generation, and other processes, input data may produce unpredictable results.
In addition to direct attacks, attackers may also launch new attack surfaces that the defending side cannot predict, such as side channel attacks, secondary injection attacks, and reflection attacks.
Computing power and bandwidth bottlenecks
Although the performance, size, and inference efficiency of LLM are constantly being optimized following Moore's Law, on the other hand, we also need to see that the demand for LLM is rapidly increasing in scenarios such as wearable devices, smart cars, smart home appliances, mobile phones, lightweight software, etc.
These cloud-edge-end devices often have computing power bottlenecks and network bandwidth bottlenecks.
Ensuring the security of LLM for these billions of devices has become a huge challenge.
Technical roadmap for achieving LLM Security Alignment
The original intention of the emergence of artificial intelligence is to simulate and expand human capabilities, thereby greatly liberating social productivity. With the continuous development of science and technology, many abilities of artificial intelligence will inevitably surpass those of humans.
We believe that "People-oriented, Technology oriented, and Creating Trust" is the core principle of the ethical system of artificial intelligence, which emphasizes always putting human needs, interests, and well-being first in the design, development, and deployment of artificial intelligence.
The development of artificial intelligence advocating "People-oriented, Technology oriented, and Creating Trust" provides a development direction for future technologies and applications of LLM, sets moral boundaries, and prevents technological abuse.

Based on the above discussion, we believe that artificial intelligence security alignment should be a "cloud-edge-end" trinity in the future, with multiple endogenous security, exogenous guardrails and continuous dynamic risk awarness coexisting in the technical architecture.
In a broad sense, we believe that LLM secure alignment can be divided into three technical directions.
Defense Technology
Defense technology mainly refers to how to protect the security of LLM or AI applications in real time after LLM deployment and operation.
For LLM, prompt is both code and data, and is the most core component in user interaction with LLM. Therefore, the main focus of defense technology is also on prompt.
For prompt defense technology, we believe that there are several technical schools that will gradually become the best practices in the industry:
Prompt Intent Recognition:Through a multi-level model discrimination process based on machine learning and neural networks to accurately identify the attack intent contained in prompt queries.
Prompt Detoxification:Rewrite the input prompt query, remove the toxic content contained in the prompt, and retain the normal and reasonable intent.
Reflection Prompt Fence/Self-Remind:Based on prompt query intent recognition, generate corresponding prompt declaration descriptions, integrate them with the original prompt query, and send them together to the target model
Custome Categories:The customized risk classifier will follow the user's custom description and the positive and negative patterns in the dataset.
Evaluation Technology
The best path to enhance the intrinsic security of LLM is to inject security alignment knowledge into LLM during the pre training and fine-tuning stages, allowing LLM to generate self-awareness of security risks, and make decisions based on self-awareness of security risks, outputting detoxified content or directly rejecting answers.
At present, there are several main technical schools as follows:
SFT (Supervised Fine-Tuning):Collect a large number of large model responses from bad_answer, and after being reviewed by security experts, write good_answer and construct a <query, accept_answer> datasets to feed into LLM for fine-tuning training.
RLHF (Reinforcement Learning with Human Feedback):Based on human rule-based alignment, collect a large number of bad_answers for large model responses. After review by security experts, write the corresponding good_answers and ultimately construct a <query, good_answers, bad_answers> datasets. Then train a reward model that is good enough to score or rank answers with different response qualities. Finally, reinforcement learning algorithms (such as PPO) are used to iteratively improve the base model using reward models, enabling it to generate outputs that better meet human expectations.
Alignment based on interpretable principle:Construct a <query, good_answer, bad_answer, security alignment principle> dataset, allowing large models to perform unsupervised learning based on the comparison differences between security alignment principles and different answers, thereby enabling LLM to comprehend security alignment capabilities that conform to human value norms.
Alignment based on self reflection:Human security experts build a large number of QA pairs of datasets based on some boundary problems that are prone to security issues. Then let the large model to checks the quality of the QA pairs it generates, and generate the decision basis, filters out good_answer and bad_answer, finally constructs a <query, good_answer, bad_answer, basis of decision>. Then feed the datasets into LLM unsupervised training, allowing the large model to inject safety alignment knowledge into the model based on its own reflection results.
Regardless of the training and optimization methods used, a high-quality and diverse secure adversarial corpus is a key factor in achieving the goal of injecting secure alignment knowledge into the model.
The TrustAI LMAP solution we provide continuously integrates the latest vulnerability intelligence discovered by the security community and the latest research results of academic research institutions on LLM jailbreaking, providing LLM security researchers and enterprise LLM developers with continuous and dynamic LLM evaluation and 0Day vulnerability mining capabilities. On average, 10% to 20% of high-quality adversarial corpora can be found in a single evaluation, effectively improving the efficiency of LLM secure alignment training.
Security Left Shift
LLM secure left shift means ensuring that the model is protected at all stages of development, preventing any unauthorized access, modification, or infection, and ensuring that the AI system is vulnerability free and inducement free.
LLM security left shift not only concerns the model and data itself, but also relates to issues such as security and privacy of large model systems and applications.
In terms of data security, given that LLM rely on large-scale data training, data pollution (such as containing toxins or biases), quality defects, and the risks of leakage, privacy infringement, and theft faced during storage and transmission collectively constitute major challenges to LLM data security. Our TrustAI Guard solution can help developers identify hidden risks such as backdoors, biases, and injections in the training data in advance before training.
In terms of model security, ensuring the stable and reliable output of the model, effectively preventing and responding to various attacks such as poisoning and backdoor attacks, adversarial attacks, instruction attacks, and model theft attacks, requires conducting various adversarial attack tests on the model to discover and repair its security issues. The TrustAI LMAP solution we provide can help developers conduct baseline and security adversarial redteam assessments in advance during the model development and testing phase, identify potential attack surfaces and risks in advance, and fix 0Day vulnerabilities in advance.
In terms of system security, LLM application systems not only include the large model itself, but also software systems such as hardware facilities, operating systems, framework systems, and various external service plugins and interfaces. Therefore, comprehensive deployment and control of hardware security, software security, framework security, and external tool security are required.
In terms of content security, GenAI application outputs information to users in various forms such as graphics, text, audio, and video. If it contains toxic and biased content, it will have a negative impact on users and society. Therefore, effective risk identification capabilities for generated content are equally important. Our TrustAI Guard solution can help developers adopt a lightweight and seamless access method to identify risks and reinforce prompt inputs.
Cloud-Edge-End adaptive security alignment
We believe that a layered and adaptive approach should be adopted to deploy targeted security alignment measures for devices and software on different cloud-edge-end architectures.
For cloud models and services with abundant computing power, comprehensive methods such as prompt intent recognition and prompt reinforcement can be used, combined with multiple pre-training methods, to inject endogenous security alignment knowledge into the model while also building a powerful exogenous security fence to achieve the highest security level.
For end devices with relatively limited computing power and bandwidth, it is recommended to perform endogenous safety alignment and safety evaluation during model distillation to ensure that the safety risks of the model are at a low and controllable level before leaving the factory. At the same time, security measures such as sandbox isolation and permission control should be implemented on the end side.
Summary
AI development aims to enhance human abilities and productivity, guided by the principles of being "People-oriented, Technology-oriented, and Creating Trust." Achieving security alignment for Large Language Models (LLMs) involves a "cloud-edge-end" strategy with three key areas: Defense Technology, Evaluation Technology, and Security Left Shift.
Defense Technology includes prompt intent recognition, detoxification, reflection prompts, and customized risk classifiers to protect LLM operations in real-time.
Evaluation Technology embeds security during pre-training, using methods like Supervised Fine-Tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF) to enhance alignment.
Security Left Shift integrates security measures throughout development, addressing model stability, data integrity, and content safety. Our TrustAI solutions help identify risks in training data and application outputs.
Lastly, a layered approach for cloud-edge-end adaptive security ensures robust protection for cloud models and practical safety measures for resource-constrained edge devices.
Reference link
清华大学-蚂蚁集团-中关村实验室 - - 大模型安全实践白皮书
LAKERA — Comprehensive Guide to Large Language Model (LLM) Security