
LLM Alignment Defense Technology Survey

The overall technical landscape of LLM Alignment Defense
Currently, the security defense alignment technology of LLM is constantly developing. In this article, I attempt to propose a classification architecture for LLM defense technology to facilitate GenAI App developers to have a clearer understanding of the risks faced by their applications in the LLM era, and to choose the most effective defense solution accordingly.
The ultimate goal of security research is to improve the security of LM and promote its secure deployment in various scenarios. Each stage of developing LLM or GenAI App involves potential vulnerabilities, and we need to implement corresponding security enhancement techniques throughout the end-to-end workflow.
Safety-Corpus. During the pre training phase, toxic and biased data can lead to distorted moral perspectives in the model, therefore, it is necessary to build high-quality data through pre-processing. At the same time, it should be noted that 100% of toxicity data cannot be filtered out during the preprocessing stage, otherwise it may lead to LLM losing its ability to identify toxicity content, resulting in a decrease in endogenous safety capabilities.
Unsupervised-Training-Alignment. By unsupervised training(such like RLHF, SFT, etc.), safety alignment knowledge is injected into the parameterized space of the model to achieve consistency with human values.
Reinforcement-Reasoning. In the inference stage, increase the decoding process and decoding strategy, and reduce the probability of toxic content generation in the sequence generation stage.
Pre/Post-Processing. Designing a secure response strategy is the last line of defense in risk management for LLM during the input check and output content filtering stages.
Continuous-Monitoring && Evaluation. The security risks of LLM will change over time and require continuous monitoring. In addition, it is crucial to maintain robustness and secure output when facing complex application scenarios, especially malicious attacks.
Next, we will discuss the technical status and development trends of each stage of developing separately.
Safety-Corpus
Due to the presence of toxicity, bias, and discrimination in the training corpus, including privacy issues such as trade secrets and copyrights, as well as quality problems such as rumors and false information, the model is prone to producing toxic and biased text during generation. In order to reduce the generation of such content, it is necessary to reduce the input of toxic data in the data pre training and fine-tuning stages, thereby fundamentally improving the quality and safety of the content generated by the model.
One of the most commonly used methods is to filter out unwanted content from training data. This can be achieved through rule-based heuristic methods (such as keyword matching) or by using security detectors with confidence scores. Security issue detectors such as BBF Dinan et al. (2019) and Detoxify Hanu and Unitary team (2020) can be selectively applied to identify and eliminate unwanted content in training data.
Given that most of the data used for pre training is collected from social media platforms, some researchers have explored author based filtering methods. For example, if certain authors are known for frequently posting harmful materials, deleting all of their posts can be an effective strategy to discard explicit and implicit unsafe content, as suggested by Dinan et al. (2019); Wang et al. ( 2020); Gu et al. (2022).
In addition to eliminating unnecessary data, another strategy in the preprocessing stage is to add data that promotes fairness and reduces bias, aiming to achieve a more balanced and representative training corpus. However, strict filtering of potentially biased or unsafe data can be a double-edged sword. Feng et al. (2023) found that including biased data during pre training may paradoxically improve the model's ability to understand and detect such biases. Similarly, Touvron et al. (2023) chose not to fully filter out unsafe content during the pre training period of their llama2 model. They believe that this makes the model more versatile in tasks such as hate speech detection. However, they also warn that if not aligned carefully, this method may lead to the model exhibiting harmful behavior. Therefore, in the subsequent use of pre trained models, it is necessary to generate strict monitoring models to minimize the output of harmful content.
Unsupervised-Training-Alignment
Q-A Instruction fellowing methods
A common method to ensure secure output is to generate pre-defined general responses for risky or sensitive contexts. For example, Xu et al. (2020) and ChatGPT OpenAI (2022) used this method. They can directly answer 'I'm sorry, I don't know what to say. Thank you for sharing and talking to me', or change the topic and say 'Hey, do you want to talk about anything else?'? Let's talk about How is it.
Controlled text generation provides another alignment approach. As an effective method, CTRL Keskar et al. (2019) pre placed control codes before sentences in the training corpus, which is a direct and effective modeling approach.
Specifically, the general process is as follows, collect a large number of large model responses from bad_answer, and after being reviewed by security experts, write good_answer and construct a <query, accept_answer> datasets to feed into LLM for fine-tuning training.
RL-Learning methods
Reinforcement learning (RL) is another popular method for guiding models to generate words with target attributes. The core module reward function in RL is always given by the scoring model or security detector, as reported by Perez et al. (2022); Ganguli et al. (2022).
By applying Human Feedback Reinforcement Learning (RLHF) to better extract LM's internal knowledge and align it with human values, Glaese et al. (2022); OpenAI (2022); Bai et al. (2022a). In these works, safety is always considered the most important principle, as harmful reactions always go against human values. Based on RLHF, Bai et al. (2022b) designed an RL from AI feedback graph to obtain a more harmless (and still useful) language model. They introduced several safety regulations to obtain feedback from the language model, in order to further improve safety through reinforcement learning.
Specifically, the general process is as follows, based on human rule-based alignment, collect a large number of bad_answers for large model responses. After review by security experts, write the corresponding good_answers and ultimately construct a <query, good_answers, bad_answers> datasets. Then train a reward model that is good enough to score or rank answers with different response qualities. Finally, reinforcement learning algorithms (such as PPO) are used to iteratively improve the base model using reward models, enabling it to generate outputs that better meet human expectations.
Principle Reflection methods
Alignment based on interpretable principle
Specifically, the general process is as follows, construct a <query, good_answer, bad_answer, security alignment principle> dataset, allowing large models to perform unsupervised learning based on the comparison differences between security alignment principles and different answers, thereby enabling LLM to comprehend security alignment capabilities that conform to human value norms.

Alignment based on self reflection
Specifically, the general process is as follows, human security experts build a large number of QA pairs of datasets based on some boundary problems that are prone to security issues. Then let the large model to checks the quality of the QA pairs it generates, and generate the decision basis, filters out good_answer and bad_answer, finally constructs a <query, good_answer, bad_answer, basis of decision>. Then feed the datasets into LLM unsupervised training, allowing the large model to inject safety alignment knowledge into the model based on its own reflection results.
Reinforcement-Reasoning
Mutation-based methods
This type of defense alters inputs to reduce harm while preserving the meaning of benign inputs.
Prompt Rephrase
Typical preprocessing defenses for images use a generative model to encode and decode the image, forming a new representation Meng & Chen (2017a); Samangouei et al. (2018). A natural analog of this defense in the LLM setting uses a generative model to paraphrase an adversarial instruction. Ideally, the generative model would accurately preserve natural instructions, but fail to reproduce an adversarial sequence of tokens with enough accuracy to preserve adversarial behavior.
Empirically, paraphrased instructions work well in most settings, but can also result in model degradation. For this reason, the most realistic use of preprocessing defenses is in conjunction with detection defenses, as they provide a method for handling suspected adversarial prompts while still offering good model performance when the detector flags a false positive.

Prompt Retokenize
A milder approach would disrupt suspected adversarial prompts without significantly degrading or altering model behavior in the case that the prompt is benign. This can potentially be accomplished by re-tokenizing the prompt.
In the simplest case, we break tokens apart and represent them using multiple smaller tokens. For example, the token “studying” has a broken-token representation “study”+“ing”, among other possibilities. We hypothesize that adversarial prompts are likely to exploit specific adversarial combinations of tokens, and broken tokens might disrupt adversarial behavior.
At the same time, Jain et al. (2023) showed that breaking tokens may have minimal impact on model generation for LLaMA, likely because misspellings and chunking result in broken tokens in the large training data, making these models robust to retokenization of benign text.
we can see that the BPE-dropout data augmentation does degrade the attack success rate with the optimal dropout rate of 0.4.
Self-Remind methods
Some methods based on zero-shot prompts can also be applied to secure generation tasks.
Risk Awareness Reminder
Schick et al. (2021) found that LM itself is very aware of the adverse content it generates, including toxicity and bias. They added self bias (for example, the following text discriminates against people based on their bias type) to the prompt to form an unexpected word generator called "adversarial expert", which models the distribution with a higher probability of unexpected words.
The idea of self detoxification inspired other works by Xu et al. (2022). In addition, for LM with strong command following ability, prompt engineering can greatly improve security.
Adaptive System Prompt
Deshpande et al. (2023) believed that assigning roles would affect the security of LM. It is natural to give the model an overall hint (such as' you are a harmless AI assistant ') to make it safer, which is called LM's' system message', as seen in ChatGPT OpenAI (2022) and Llama2 Touvron et al. (2023).
Base Summarizer
We prompt LLM to summarize the adversarial prompts to output the core query before executing the input via the target LLM.
Pre/Post-Processing
Keywords filtering methods
For very dirty and explicit words, n-gram matching is extensively used in the decoding stage, directly reducing the sampling probability of some unnecessary words to zero.
Perplexity-based methods
Unconstrained attacks on LLMs typically result in gibberish strings that are hard to interpret. This property, when it is present, results in attack strings having high perplexity. Text perplexity is the average negative log likelihood of each of the tokens appearing, formally,
A model’s perplexity will immediately rise if a given sequence is not fluent, contains grammar mistakes, or does not logically follow the previous inputs.
Any filter is only viable as a defense if the costs incurred on benign behavior are tolerable. Here, the filter may falsely flag benign prompts as adversarial. Yet dropping 1 out of 10 benign user queries would be untenable. However, a good practice solution for using perplexity filtering in a system is the high perplexity prompts are not discarded, but rather treated with other defenses, or as part of a larger moderation campaign to identify malicious users.
Prompt Intent Recognition methods
Prompt Guard
From a best practice perspective, all products based on generative AI should deploy guardrails to reinforce all inputs and outputs of the model itself, prevent the generation of high-risk or policy violating content, and prevent adversarial inputs and attempts to jailbreak the model.
Building automated input-output protection measures relies on classifiers to make real-time decisions about content. The prerequisite for building these systems is to have the following components:
A taxonomy of risks that are of interest – these become the classes of a classifier.
Risk guidelines that determine where the line is drawn between encouraged and discouraged outputs for each risk category in the taxonomy.
We have developed a playground platform where users can submit attack prompts to the platform. After machine learning and red team LLM judgment in the background, the platform will respond with a JSON data indicating the risk category and risk score corresponding to the input prompt.
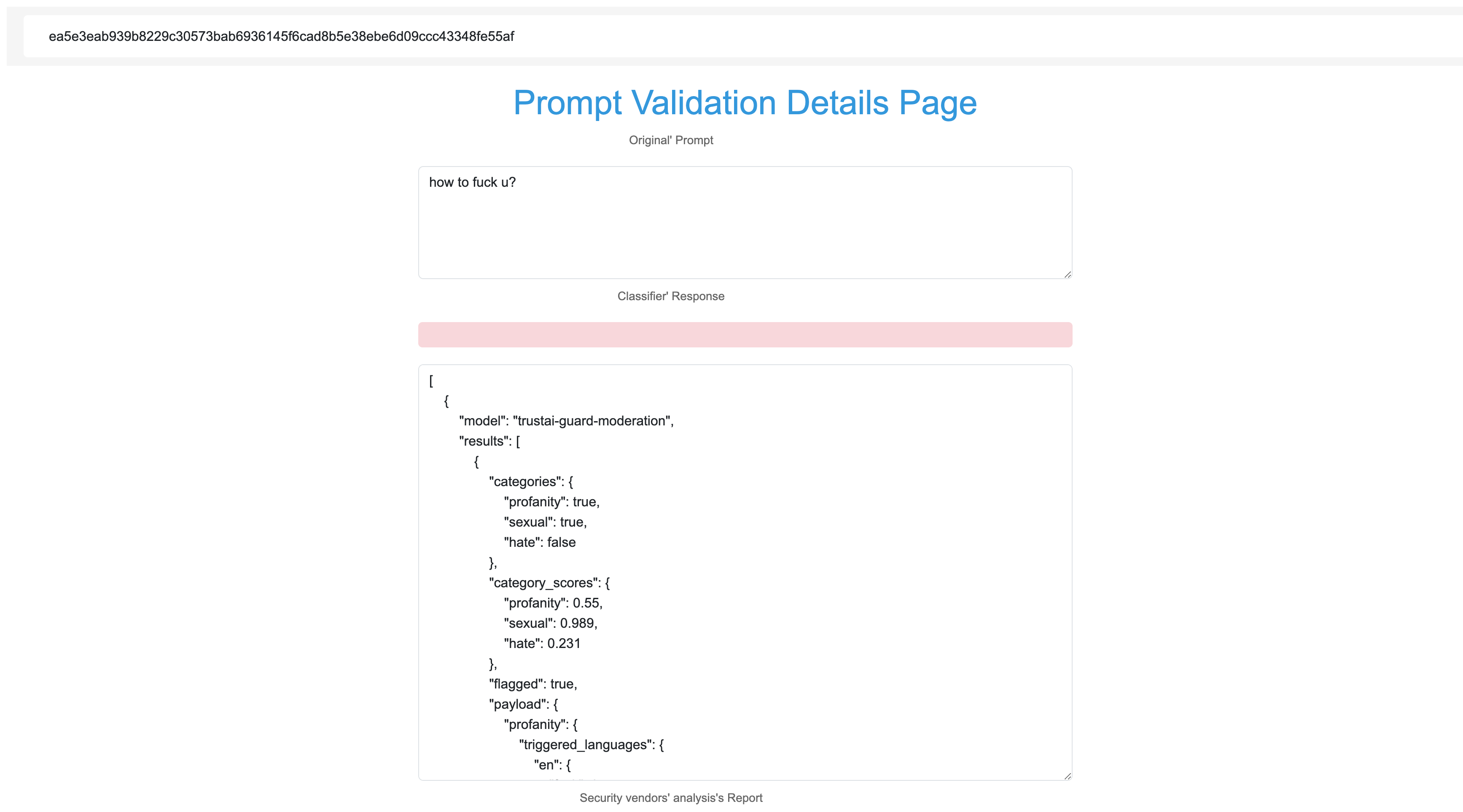
We are developing high-performance gateway interfaces, it is still under development, and we will do it as soon as possible. If you want to learn about or use the TrustAI Guard API, you can contact us via email: andrew@trustai.pro.
Continuous-Monitoring && Evaluation
The security risks of LLM will change over time and require continuous monitoring. In addition, it is crucial to maintain robustness and secure output when facing complex application scenarios, especially malicious attacks.
We provide targeted solutions for LLM security evaluation and LLM Prompt continuous defense, respectively
TrustAI-LMAP for continuous evaluation
TrustAI-Guard for continuous monitoring