
Let's talk about LLMs Hallucinations

Introduction
Monitoring hallucinations is fundamental to delivering correct, safe, and helpful large language model (LLM) applications. Hallucinations — instances where AI models generate outputs not grounded in factual accuracy — pose significant challenges.
 surrounded by abstract, whimsical elements representing hallucinations, such as floating words, distorted objects, and surreal landscapes. The overall style is modern, dynamic, and cheerful, with bright colors and a mix of technology and fantasy elements. The text 'Let's Talk About LLMs Hallucinations' is prominently displayed in a bold, friendly font.")
Why Hallucinations Happen in LLMs?
Hallucinations occur when LLMs, which have been trained on extensive text corpora, attempt to predict the next token or sequence of tokens based on the data they have been trained on. These models lack an understanding of truth or the factual accuracy of their outputs. The content generated by these models is based on statistical likelihoods rather than factual correctness. This means that while the AI might produce text that is statistically plausible within the context of its training data, it does not have the capability to discern or ensure truthfulness.
Because the model operates purely on statistical prediction without awareness of truth, the outputs may sometimes appear to "make stuff up." This can result in outputs that are not only inaccurate but also potentially misleading or harmful if taken at face value.
As a result, there are significant risks associated with AI hallucinations, especially when such outputs are used in critical applications. The LLM's inability to distinguish between factual and fabricated content can pose serious implications, making it a top concern for enterprises.
Concerns and Challenges in Hallucinations
Hallucinations in LLMs pose considerable concerns and challenges that deter enterprises from widely adopting and implementing the use of LLM applications. Key challenges include:
Safety: One of the primary concerns with hallucinations in AI, particularly in critical applications, is the safety risk they pose. Inaccurate or misleading information can lead to decisions that jeopardize user safety, such as incorrect medical advice or faulty navigation instructions.
Trust: Hallucinations can significantly erode trust in AI systems. Users rely on AI for accurate and trustworthy information, and frequent inaccuracies can lead to distrust, reducing the adoption and effectiveness of AI technologies across various sectors.
Implementation Challenges: Detecting and mitigating hallucinations pose significant implementation challenges. LLMs are complex and require sophisticated techniques to monitor and correct hallucinations effectively. This complexity can hinder the deployment of reliable LLM applications.
Regulatory and Ethical Issues: There are regulatory and ethical implications to consider. As LLM applications are more widely adopted, they must comply with increasing regulatory standards that govern data accuracy and user safety. Ensuring that LLM applications do not hallucinate misleading information becomes not only a technical challenge but also legal and ethical risks.
Resource Intensity: Monitoring and mitigating hallucinations require significant computational resources and expertise. The need for ongoing evaluation and updates to AI models to address hallucinations can be resource-intensive, impacting the scalability and sustainability of LLM projects.
Barrier to Widespread Adoption: Persistent issues with hallucinations can act as a barrier to the wider adoption of AI technologies. If enterprises and consumers perceive AI as risky due to unaddressed hallucinations, this perception can slow down the integration of AI into everyday applications.
Hallucinations can affect important choices, such as court cases or when dealing with a company's reputation, like what happened with Google’s Bard. They can also expose private information the model saw during training, cause mistakes in medical diagnoses due to incorrect patient summaries, or simply lead to a frustrating chatbot experience that can't answer a basic question.
Types of Hallucinations
"Intrinsic Hallucinations:" These are made-up details that directly conflict with the original information. For example, if the original content says "The first Ebola vaccine was approved by the FDA in 2019," but the summarized version says "The first Ebola vaccine was approved in 2021," then that's an intrinsic hallucination.
"Extrinsic Hallucinations:" These are details added to the summarized version that can't be confirmed or denied by the original content. For instance, if the summary includes "China has already started clinical trials of the COVID-19 vaccine," but the original content doesn't mention this, it's an extrinsic hallucination. Even though it may be true and add useful context, it's seen as risky as it's not verifiable from the original information.
Let's have a look at hallucinations in different generative tasks:

Generative task 1: Abstractive summarisation
Abstractive summarization is a method used to pick out important details from documents and create short, clear, and easy-to-read summaries. These have seen impressive results when done with neural networks. However, studies have found issues, such as these models often producing misleading content that doesn't match the original document. It's shown that 25% of the summaries from the best current models have this problem [Falke et al.]. Summaries with a lot of misleading content can still get a higher ROUGE score [Lin et al.].
There are two types of hallucination in summarization:
intrinsic, where the summary says something opposite to the original text
extrinsic, where the summary includes something not mentioned in the original at all.
For example, if an article says the FDA approved the first Ebola vaccine in 2019, an intrinsic hallucination would be to say the FDA rejected it. An extrinsic hallucination example might be to claim that China has started testing a COVID-19 vaccine when the original article doesn't mention that at all.
In addition to this, Pagnoni and his colleagues describe more detailed types of factual errors in summaries.

Generative task 2: Dialogue generation
In open domain dialogue generation, a chatbot either gives the user necessary details or keeps them interested with new replies without rehashing previous conversation. A little bit of hallucination might be acceptable in this context.
Intrinsic hallucination is when the chatbot's response contradicts the previous conversation or external knowledge.
Extrinsic hallucination happens when we can't cross-check the chatbot's response with previous dialogue or outside knowledge.
Now, let's talk about open-domain dialogue creation. Inconsistency within the bot's responses is a type of intrinsic hallucination, while inconsistency with outside sources can be either intrinsic or extrinsic hallucination.
In open-domain conversation, a little hallucination may be fine as long as it doesn't include serious factual errors. But it's usually hard to verify the facts because the system doesn't usually have access to outside resources. In these systems, inconsistencies in the bot's replies are often seen as the main problem. You can see this when a bot gives different answers to similar questions, like “What's your name?” and “May I ask your name?” A focus here is the bot's persona consistency - its identity and interaction style - and making sure it doesn't contradict itself. Aside from this, a chatbot in the open domain should provide consistent and informative responses that align with the user's speech to keep the conversation engaging. External resources with specific persona information or general knowledge can help the chatbot create responses.
Generative task 3: Retrieval Augmented Generation
Retrieval Augmented Generation(RAG) is a system that creates in-depth responses to questions instead of just pulling out answers from given texts. This is useful because many questions people ask on search engines need detailed explanations. These answers are typically long and can't be directly taken from specific phrases.
Usually, a GQA system looks for relevant information from different sources to answer a question. Then, it uses this information to come up with an answer. In many instances, no single document has the complete answer, so multiple documents are used. These documents might have repeating, supporting, or conflicting information. Because of this, the generated answers often contain hallucinations.
Generative task 4: Neural machine translation

Intrinsic errors occur when the translation includes incorrect details compared to the original text. For example, if the original text mentions "Mike" but the translation says "Jerry doesn’t go," that's an intrinsic error.
Extrinsic errors happen when the translation adds new information that wasn't in the original text. For example, if the translation includes "happily" or "with his friend" but these details aren't in the original text, that's an extrinsic error.
There are also other ways to classify these errors. One group suggests splitting them into errors seen with altered test sets and natural errors. The first type can be seen when changing the test set drastically alters the translation. The second type, natural errors, is connected to errors in the original dataset. These can be split again into detached and oscillatory errors [Raunak et al.]. Detached errors happen when the translation doesn't match the meaning of the original text. Oscillatory errors happen when the translation repeats phrases that weren't in the original text.
Other errors include suddenly skipping to the end of the text or when the translation is mostly in the original language. These are all considered types of hallucination errors in machine translation.
Generative task 5: Data to text generation
Data-to-Text Generation is the process of creating written descriptions based on data like tables, database records, or knowledge graphs.
Intrinsic Hallucinations is when the created text includes information that goes against the data provided. For instance, if a table lists a team's win-loss record as 18-5, but the generated text says 18-4, that's an Intrinsic Hallucination.
Extrinsic Hallucinations is when the text includes extra information that isn't related to the provided data. An example would be if the text mentioned a team's recent wins, even though that information wasn't in the data.
Techniques for Detecting LLM Hallucinations
1. Log probability
The first technique comes from the paper Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation (Guerreiro et al. 2023).
Summary: In this paper the authors explore different detection techniques, reevaluating previous methods and introducing glass-box uncertainty-based detectors. The findings reveal that established methods are inadequate for preventive scenarios, with sequence log-probability proving most effective, comparable to reference-based methods. Additionally, the report introduces the DeHallucinator method, a straightforward approach that significantly reduces hallucination rates.
This paper proposes Seq-Logprob which calculates the length-normalized sequence log-probability for each word in the generated translation y for a trained model P (y|x, θ).

If a model is "hallucinating," it is likely not confident in its output. This means that the lower the model's confidence (as measured by Seq-Logprob), the higher the chance that it will produce a poor translation. This matches findings from previous studies on translation quality. Internal model characteristics may contain a lot more information than we expect.
2. Sentence Similarity
The second paper is Detecting and Mitigating Hallucinations in Machine Translation: Model Internal Workings Alone Do Well, Sentence Similarity Even Better (David et al. Dec 2022)
Summary: This paper proposes evaluating the percentage of source contribution to generated translations and identifying hallucinations by detecting low source contribution. The team found this technique significantly enhances detection accuracy for severe hallucinations, outperforming previous approaches that relied on external models. They also found that sentence similarity from cross-lingual embeddings can further improve detection and mitigation of hallucinations.

3. SelfCheckGPT
The third technique comes from SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models (Manakul et al. 2023)
Summary: This paper evaluates techniques for hallucination using GPT when output probabilities are not available, as is often the case with black box which don’t provide access to output probability distributions. With this in mind, this technique explores three variants of SelfCheckGPT for assessing informational consistency.
SelfCheckGPT with BERTScore
SelfCheckGPT uses BERTScore to calculate the average BERTScore of a sentence when compared with the most similar sentence from each selected sample. If the information contained in a sentence is found across many selected samples, it is reasonable to conclude that the information is factual. On the other hand, if the statement does not appear in any other sample, it may likely be a hallucination or an outlier.
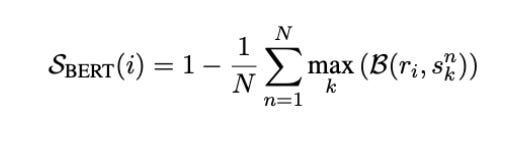
Here r_i refers to the i-th sentence in R, and s_nk refers to the sentence in the drawn samples.
SelfCheckGPT with Question Answering
They incorporate the automatic framework of multiple-choice question answering generation (MQAG) [Manakul et al.] into SelfCheckGPT. MQAG facilitates consistency assessment by creating multiple-choice questions that a separate answering system can answer for each passage. If the same questions are asked it's anticipated that the answering system will predict the same answers. The MQAG framework is constructed of three main components: a question-answer generation system (G1), a distractor generation system (G2), and an answering system (A).
For each sentence r_i within the response R, they formulate the corresponding questions q, their answers a and the distractors o_a. To eliminate unanswerable queries, they assign an answerability score. They utilize α to exclude unanswerable queries which have an α lower than a certain limit. Then they use the answering system to answer all the answerable questions. They compare answers from a sample with answers from all other samples. This gives us the matches(N_m) and non matches(N_n). They calculate a simple inconsistency score for ith sentence and qth question using Bayes theorem as shown below. Here N_m′ = the effective match count, N_n′ = the effective mismatch count, γ1, and γ2 are defined constants.
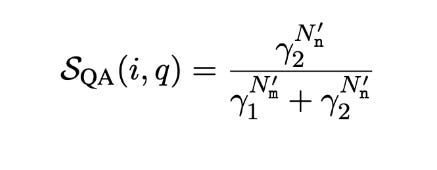
Final score is the mean of inconsistency scores across q.
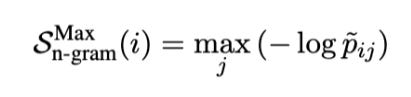
SelfCheckGPT Combination
Since different variants of SelfCheckGPT have different characteristics, they can provide complementary outcomes. They propose SelfCheckGPT-combination which integrates normalized scores from all the variants - S_bert, S_qa and S_ngram.
4. GPT4 prompting
The fourth technique comes from the paper Evaluating the Factual Consistency of Large Language Models Through News Summarization (Tam et al. 2023)
Summary: This paper focuses on the summarization use case and surveys different prompting techniques and models to find the best ways to detect hallucinations in summaries.
The authors try 2 types of prompting:
Chain-of-thought prompting: They design chain-of-thought instruction which forces the model to generate the information from the document before giving the final conclusion.
Sentence-by-sentence prompting: They break the summary into multiple sentences and verify facts for each.
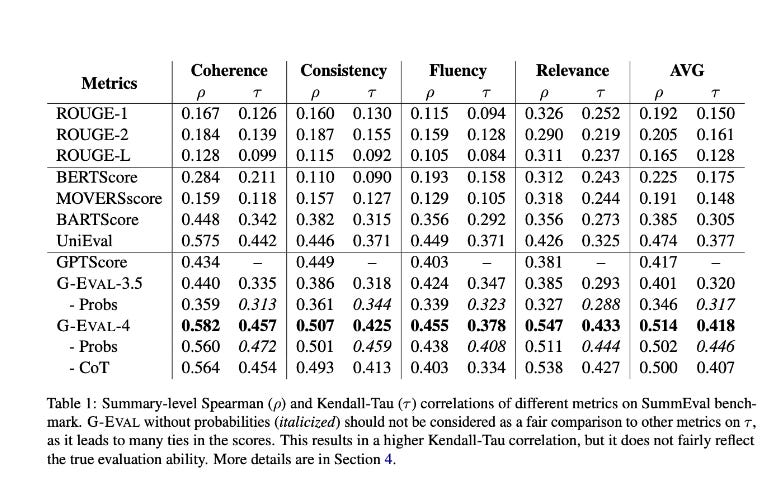
5. G-EVAL
The fifth technique comes from the paper G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment(Liu et al. 2023)
Summary: This paper proposes a framework for LLMs to evaluate the quality of NLG using chain of thoughts and form filling. They experiment with summary and dialogue generation datasets and beat previous approaches by a large margin.
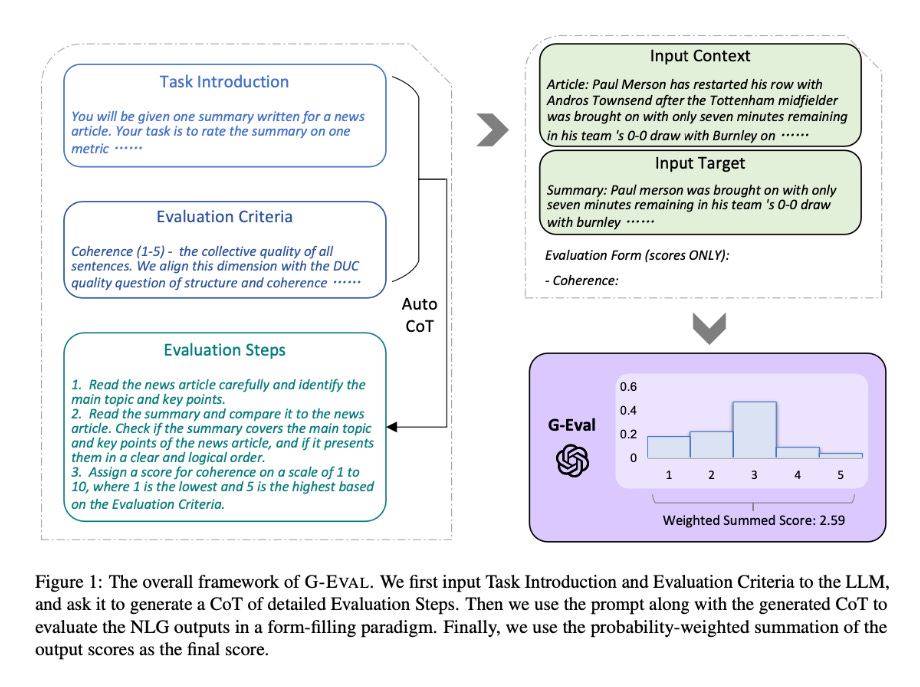
G-EVAL comprises three primary elements:
a prompt defining the evaluation task and criteria,
a chain-of-thoughts (CoT) consisting of intermediate instructions generated by the LLM for detailed evaluation steps
a scoring function that utilizes the LLM to calculate scores based on returned token probabilities.
Overall G-EVAL-4 outperforms all other state of the art techniques by a large margin. This technique also performs well on QAGS-Xsum which has abstractive summaries.
The below prompt shows how hallucination is evaluated.

The below prompt shows how coherence is evaluated.

Key metrics to monitor LLM Hallucinations
Monitoring and evaluating LLM responses for hallucinations is essential for maintaining model performance. Key metrics to monitor include:
Perplexity: A measure of how well the probability distribution predicted by the model matches the observed outcomes; higher perplexity may indicate more frequent hallucinations.
Semantic Coherence: Evaluating whether the text is logically consistent and stays relevant throughout the discourse.
Semantic Similarity: Determine how closely the language model's responses align with the context of the prompt. This metric is useful for understanding whether the LLM is maintaining thematic consistency with the provided information.
Answer/Context Relevance: The importance of ensuring that the model not only generates factual and coherent responses but also that these responses are contextually appropriate to the user's initial query. This involves evaluating whether the AI’s output is directly answering the question asked or merely providing related but ultimately irrelevant information.
Reference Corpus Comparison: Analyzing the overlap between AI-generated text and a trusted corpus helps identify deviations that could signal hallucinations.
Monitoring Changes: Monitoring how well the LLM adapts to changes in the context or environment it operates in is also important. For instance, if new topics or concerns arise that were not part of the original training data, the LLM might struggle to provide relevant answers. Prompt injection attacks or unexpected user interactions can reveal these limitations.
Prompt and Response Alignment: Both the retrieval mechanism (how information is pulled from the database or corpus) and the generative model (how the response is crafted) must work harmoniously to ensure that responses are not only accurate but also relevant to the specific context of the query.
Reducing Risks Associated with LLM Hallucinations
Key practices for reducing hallucinations and improving the correctness and safety of LLM applications include:
Observability: Implementing a comprehensive AI observability solution for LLMOps is critical to ensuring LLM performance, correctness, safety, and privacy. This allows for better monitoring of LLM metrics, and enables quicker issue identification and resolution related to hallucinations.
Evaluation and Testing: Rigorous LLM evaluation and testing prior to deployment are vital. Evaluating models thoroughly during the pre-deployment phase helps in identifying and addressing potential hallucinations, ensuring that the models are trustworthy in production.
Feedback Loops: Utilizing feedback loops is an effective approach for mitigating hallucinations. LLM applications can be improved by analyzing production prompts and responses.
Guardrails: Implementing strict operational boundaries and constraints on LLMs helps prevent the generation of inappropriate or irrelevant content. By clearly defining the limits of what the AI can generate, developers can greatly decrease the occurrence of hallucinated outputs, ensuring that the responses are safe, correct, and ensure alignment with human values/expectations.
Human Oversight: Including human reviewers in the process, particularly for critical applications, can provide an additional layer of scrutiny that helps catch and correct errors before they affect users.
Fine-Tuning: Adjusting model parameters or retraining models with additional data that specifically targets identified weaknesses can improve the models' accuracy and reduce the chances of hallucination. This approach helps align the model outputs more closely with reality, addressing any gaps or hallucinations that were initially present.
While LLMs offer significant opportunities to generate new revenue streams, enhance customer experiences, and streamline processes, they also present risks that could harm both enterprises and end-users. Rigorous testing and evaluation before LLM deployment, establishing clear operational boundaries, and incorporating human oversight are critical to mitigate the risk of LLM hallucinations. Furthermore, continuous monitoring and feedback loops, coupled with strategic fine-tuning, are vital to ensure that LLM applications not only meet but exceed our standards for safety and trustworthiness. As we integrate AI more deeply into various aspects of our lives, it is crucial to remain vigilant and proactive, paving the way for more responsible AI development that benefits all users.
Conclusion
The advancements in Transformer-based language models have greatly enhanced the capabilities of Natural Language Generation. However, the occurrence of 'hallucinations,' where the AI fabricates incorrect or out-of-context details, pose significant challenges. These inaccuracies can occur in various tasks such as abstractive summarization, dialogue generation, generative question answering, machine translation, data-to-text generation, and vision-language model generation.
Addressing the issue of hallucinations in AI is crucial to increase the reliability and usability of such systems in real-world applications. By continuing research and development in these areas, we can hope to mitigate these issues and leverage the full potential of AI in language understanding and generation tasks. We will look into ways to mitigate it in our next posts.