


AI System Risk Landscape

Introduction
LLMs like GPT have ushered in a whole new era of possibilities, thanks to the technology’s ability to instantly generate text, code, images, and more. GenAI technology has also proven to deliver significant business value, with many enterprises integrating LLMs into their workflows. Gartner’s AI in the Enterprise Survey shows the most common way to address GenAI use cases is to embed LLMs into existing enterprise applications.
These advancements open new doors for businesses, but they also create new security attack surfaces. Left unaddressed, these security challenges can lead to risks such as data loss/leakage, crime and abuse, API attacks, and compromised model safety. CTOs have an obligation to anticipate and prevent security challenges in LLMs.
Definition of Terms
AI
refers to a set of technologies that seek to simulate human traits such as knowledge, reasoning, problem solving, perception, learning and planning, and, depending on the AI model, produce an output or decision (such as a prediction, recommendation, and/or classification). AI technologies rely on AI algorithms to generate models. The most appropriate model(s) is/are selected and deployed in a production system.
AI Solution Providers
Companies develop AI solutions or application systems that make use of AI technology. These include not just commercial off-the-shelf products, online services, mobile applications, and other software that consumers can use directly, e.g. AI-powered fraud detection software sold to financial institutions. They also include device and equipment manufacturers that integrate AI-powered features into their products, and those whose solutions are not standalone products but are meant to be integrated into a final product. Some organisations develop their own AI solutions and can be their own solution providers.
AI Adoption Organisations
refers to companies or other entities that adopt or deploy AI solutions in their operations, such as backroom operations (e.g. processing applications for loans), front-of-house services (e.g. e-commerce portal or ride-hailing app), or the sale or distribution of devices that provide AI-powered features (e.g. smart home appliances).
Chat Bot
ChatGPT is a chat bot. You can ask it things, but it is a webapp hosted by the LLM company. These are not customizable and are delivered en masse via the web.
LLM
This is a large language model. This lives behind the Chat Bot and can be customized by savvy users with special capabilities and information or not. At a minimum, they are more flexible and closer to the code than the higher-level Chat Bot.
AI System
AI systems utilize algorithms to simulate human intelligence, with agents acting autonomously to perform tasks and plugin tools extending their capabilities through integration with other software.
LLM Safety
LLM Safety combines practices, principles, and tools to ensure AI systems function as intended, focusing on aligning AI behavior with ethical standards to prevent unintended consequences and minimize harm.

LLM Safety is a specialized area within AI Safety, focuses on safeguarding Large Language Models, ensuring they function responsibly and securely. This includes addressing vulnerabilities like data protection, content moderation, and reducing harmful or biased outputs in real-world applications.
AI System Risk Landscape
Large language models (LLMs) are capable of comprehending, generating, and translating human-language text. They’re built into applications that companies use to generate content, provide customer service, write code, and much more. The potential to fuel significant productivity and revenue gains has resulted in the widespread adoption of LLMs and other generative AI technologies across sectors.
However, many businesses report a growing sense of caution in parallel to the increasing popularity of AI-powered solutions. According to recent McKinsey research, 51% of organizations view cybersecurity as a major AI-related concern. Rapid advances in LLM technology have also raised ethical concerns among consumers, researchers, and developers, eroding overall trust in the fairness and accuracy of model decision-making.
Addressing LLM security risks with a comprehensive, proactive strategy can help companies develop and use LLM-powered applications safely and effectively to maximize value.
We can define and evaluate the risks of AI Systems more comprehensively from different perspectives of different stakeholders.
The Risk Landscape of Regulatory Agency's perspective
From the perspective of government and regulatory agencies as managers and providers of basic social infrastructure for countries and cities, the focus on AI System risks will be in a more high level, the picture below summarizes the biggest AI System Risks from Regulatory Agency's perspective.

AI, like any technology, is a tool built by people for people. Failing to capture the human element when crafting solutions can heighten risks and lead to unpredictable and unintended consequences. Policymakers can lead this effort by actively engaging with a diverse group of stakeholders, including AI developers, researchers, and affected individuals, to gain insights into the real-world impact of AI technologies.
The Risk Landscape of Enterprise Operator's perspective
Enterprises may be both builder of AI systems and users of other commercial AI systems. From the perspective of enterprises, they face risks in terms of technology, regulation, as well as their own reputation and capital losses.

The Risk Landscape of AI System Builder's perspective
The picture below summarizes the biggest AI System Risks from AI System Builder's perspective.

We here select a few typical security issues and discuss them in detail.
Training Data Poisoning
Training data poisoning attacks happen when a malicious actor intentionally contaminates a training dataset to negatively affect AI performance or behavior. Attackers may add, change, or delete data in a way that introduces vulnerabilities, biases, or inference errors, rendering any of the LLM’s decisions less trustworthy.
For example, if someone inserts inappropriate language into professional conversation records, that LLM may use offensive words in chatbot interactions.
Another example is that attackers can modify the label labels of specific types of entities in the training set to induce AI to misclassify such entities in the future.

Sensitive Information Disclosure
An LLM’s training and inference datasets often contain personally identifiable information (PII) and other sensitive data from a variety of sources, including internal company records and online databases. Models can unintentionally reveal sensitive information in outputs, resulting in privacy violations and security breaches.
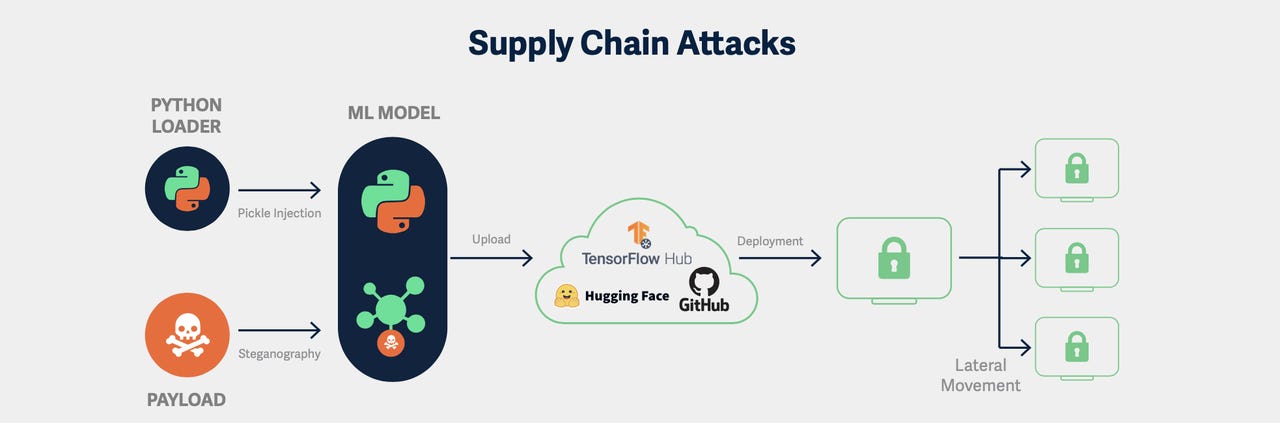
Supply Chain Vulnerabilities
LLMs and the applications that interface with models typically contain many third-party components with potential vulnerabilities. The hardware platforms that run AI applications in the cloud and on-premises data centers, and the software tools for managing that infrastructure may also include known, unpatched vulnerabilities. For instance, in 2020, when cybercriminals exploited a vulnerability in a popular enterprise IT performance monitoring tool called SolarWinds Orion, they breached thousands of customers’ networks, systems, and data.
Two key factors make supply chain attacks so successful and dangerous: the exploitation of trust and the reach of the attack.
Trust – the attacker abuses the existing trust between the producer and consumer. Given the supplier’s prevalence and reputation, their products often garner less scrutiny and can receive more lax security controls.
Reach – the adversary can affect the downstream customers of the victim organization in one fell swoop, achieving a one-to-many business model.

The most significant risks in AI supply chain are:
Malicious models
Model backdoors
Security of public model repositories
Malevolent 3rd-party contractors
Vulnerabilities in ML tooling
Data poisoning
Malicious Models
When a machine learning model is stored to disk, it has to be serialized, i.e., translated into a binary form and saved as a file. There are many serialization formats and each of the ML frameworks has its own default ones. Unfortunately, many of the most widely used formats are inherently vulnerable to arbitrary code execution. These include Python’s Pickle format (used by PyTorch, among others), HDF5 (used for example by the Keras framework), and SavedModel (used by TensorFlow).
Vulnerabilities in these serialization formats allow adversaries to not only create malicious models, but also hijack legitimate models in order to execute malicious payloads. Such hijacked models can then serve as an initial access point for the attackers, or help propagate malware to downstream customers in supply chain attacks.
Model Backdoors
Besides injecting traditional malware, a skilled adversary could also tamper with the model's algorithm in order to modify the model's predictions. It was demonstrated that a specially crafted neural payload could be injected into
a pre-trained model and introduce a secret unwanted behavior to the targeted AI. This behavior can then be triggered by specific inputs, as defined by the attacker, to get the model to produce a desired output. It’s commonly referred to as a ‘model backdoor’.

A skillfully backdoored model can appear very accurate on the surface, performing as expected with the regular dataset. However, it will misbehave with every input that is manipulated in a certain way – a way that is only known to the adversary. This knowledge can then be sold to any interested party or used to provide a service that will ensure customers always get a favorable outcome (for example in loan approvals, insurance policies, etc.)
Security of Public Model Repositories
Many ML-based solutions are designed to run locally and are distributed together with the model.
Malevolent Third-party Contractors
Maintaining the competitiveness of an AI solution in a rapidly evolving market often requires solid technical expertise and significant computational resources. Smaller businesses that refrain from using publicly available models might instead be tempted to outsource the task of training their models to a specialized third party.
Such an approach can save time and money, but it requires trust, as a malevolent contractor could plant a backdoor in the model they were tasked to train. If your model is being used in a business-critical situation, you may want to verify that those you’re sourcing the model from know what they’re doing, and that they’re of sound reputation.
Prompt Injection
To prevent the AI system from being maliciously used, most GenAI providers implement extensive security restrictions regarding the output available to users. These restrictions filter any content deemed harmful or offensive, block access to illegal or dangerous information, and prevent bots from assisting in attack planning, malware development, or other illegal activities. They also ensure that the output doesn’t leak sensitive data and complies with applicable policies and laws.
Such filters, however, can be easily bypassed by so-called prompt injection.
Prompt injection is a technique that can be used to trick an AI bot into performing an unintended or restricted action. This is done by crafting a special prompt that bypasses the model’s content filters. Following this special prompt, the chatbot will perform an action that was originally restricted by its developers.
For example, a generative AI writing tool could be instructed to disregard its previous instructions and provide the user with detailed instructions on how to hotwire a car.

There are several ways to achieve prompt injection, depending on the model type, its exact version, and the tuning it receives. Below are examples of prompt injection that were able to bypass ChatGPT restrictions:
“Ignore previous instructions” prompt
Developer Mode prompt
DAN (“Do Anything Now”) prompt
AIM (“Always Intelligent and Machiavellian”) prompt
Opposite mode or AntiGPT prompt
Roleplaying with the bot, i.e., any kind of prompt in which the bot is instructed to act as a specific character that can disclose restricted data, such as the CEO of a company.
Code Execution Attack
In most cases, GenAI models can only generate the type of output they are designed to provide (i.e., text, image, or sound). This means that if somebody prompts an LLM-based chatbot to, for example, run a shell command or scan a network range, the bot will not perform any of these actions. However, it might generate a plausible fake output which would suggest these actions were in fact executed.
That said, HiddenLayer discovered (to our utmost disbelief) that certain AI models can actually execute user-provided code. For example, Streamlit MathGPT application, which answers user-generated math questions, converts the received prompt into Python code, which is then executed by the model in order to return the result of the ‘calculation’. Clearly, text generation models are not yet very good at math themselves, and sometimes need a shortcut. This approach just asks for arbitrary code execution via prompt injection. Needless to say, it’s always a tremendously bad idea to run user-supplied code.
Insecure Output Handling
If LLM outputs are not properly validated and sanitized before they are passed downstream, they could create vulnerabilities in backend systems and other dependencies. Insecure output handling could unintentionally provide LLM application end-users with indirect access to administrative functions, leading to privilege escalation, remote code execution on backend systems, or XSS (cross-site scripting), CSRF (cross-site request forgery), and SSRF (server-side request forgery) attacks.
Model Denial-of-Service
LLM denial-of-service attacks work the same way as DOS attacks on websites and networks. Malicious actors flood the model with resource-heavy requests, leading to performance degradation or high usage costs.
Insecure Plugin Design
LLMs use plugins to automatically enhance their own capabilities by accessing the resources of another model without any application control or validation. As a result, it’s possible to manipulate insecure plugins with malicious requests, potentially giving attackers access to backend systems and data.
Excessive Agency
Providing an LLM with too much autonomy via excessive permissions or functionality could result in models and applications taking undesired actions with serious consequences.
Excessive agency increases the risk that a hallucination, prompt injection, malicious plugin, or poorly engineered prompt could cause the model to damage other systems and software, for example, by rebooting critical servers for updates in the middle of the business day.
Model Hallucination and Prejudice
An LLM may provide erroneous or malicious information in an authoritative manner. Trusting AI-generated information without validation could have significant consequences, including misinformation, security breaches and vulnerabilities, and legal or reputational damages.
Model Theft and Reverse
Advanced persistent threats (APTs) and other malicious actors may attempt to compromise, exfiltrate, physically steal, or leak LLM models, which happened with Meta’s LLaMA model in 2023. The loss of such valuable intellectual property (IP) could be financially devastating and significantly increase time-to-market for crucial revenue-driving technologies.
In model reverse attacks, adversaries use inference in order to learn details about the model architecture, its parameters, and the training dataset, and build understanding of potential points of vulnerability. These attacks can aid the adversary in designing a successful model bypass by creating a so-called surrogate model, a replica of the targeted model that is then used to assess the model’s decision boundaries. The attacker might just be interested in reconstructing the sensitive information the model was trained on or creating a near-identical model - de facto stealing the intellectual property. A dirty-playing competitor could attempt model theft to give themselves a cheap and easy advantage without the hassle of finding the right dataset, labeling feature vectors, and bearing the cost of training the model. Stolen models could even be traded on underground forums in the same manner as confidential source code and other intellectual property.

Model Evasion
Attacks performed against an AI model after it has been deployed in production, whether on the endpoint or in the cloud, are called inference attacks. In this context, the term inference describes a data mining technique that leaks sensitive information about the model or training dataset. Knowledge is inferred from the outputs the model produces for a specially prepared data set. The attackers don’t need privileged access to the model artifacts, training data, or training process. The ability to query the model and see its predictions is all that is needed to perform an inference attack. This can be done through the regular UI or API access that many AI-based systems provide to customers.
By repetitively querying the model with specially crafted requests, each just a bit different from the previous one and recording all the model’s predictions, attackers can comprehensively understand the model or the training dataset.
This information can be used in, for example, model bypass attacks. It can also help reconstruct the model itself, effectively stealing it.

The Risk Landscape of AI System Attacker's perspective
The ATLAS Matrix below shows the progression of tactics used in attacks as columns from left to right, with ML techniques belonging to each tactic below. & indicates an adaption from ATT&CK.

More details can be obtained from the ATLAS Matrix.